文|鑭瞳AI
345億孖展,超百億給了數採公司——先是大模型,然後是本體、供應鏈,資本又再次會師於數據深水區。當本體硬件創新已收斂,全行業都不得不直面「數據荒」,這是塊硬骨頭,所以更需提早籌謀。
鑭瞳AI根據已公開宣發信息統計,截至5月初,機器人賽道今年以來總孖展至少已達345億元。其中,已有超百億資金精準砸向數據採集領域。
數據採集中心與「數據工廠」蜂擁上馬,「百萬小時級數據」成了行業標配。當前行業形成分工明確的三類業態:
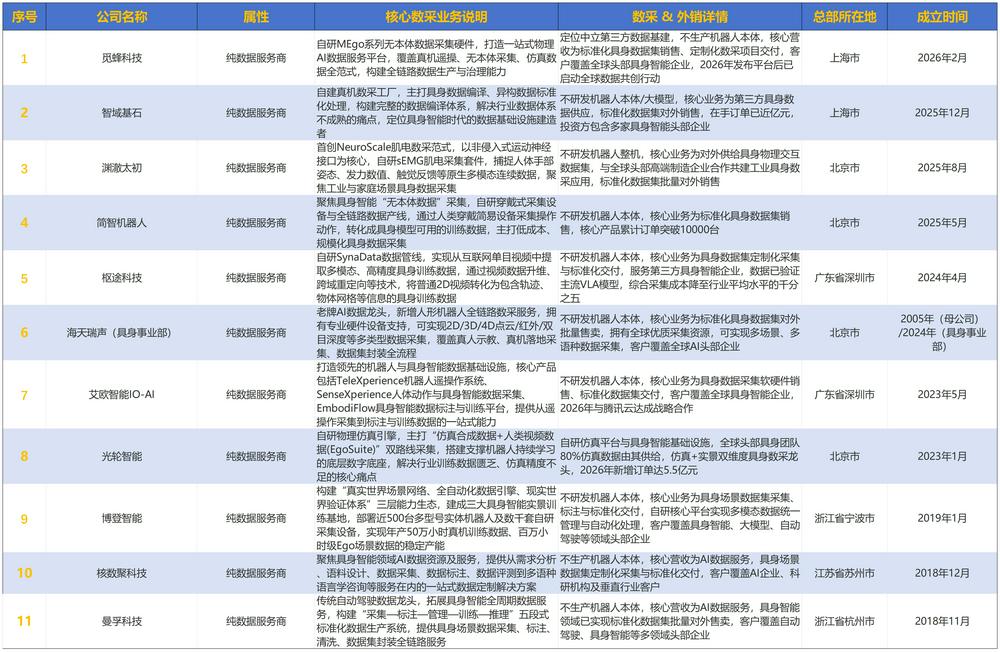
一是純數據服務商,無自研人形整機,以數據銷售為核心營收,專注多模態數據採集、清洗、封裝全鏈路服務,為全行業提供標準化、定製化數據集;
二是硬件、模型、本體廠商依託自有機器人與核心傳感硬件搭建數採體系,數採為自研迭代配套基建,將數據採集深度綁定自有硬件或模型研發,通過數據飛輪提升產品性能。在滿足自用模型訓練需求後,將標準化數據集對外外銷,作為業務增量;
三是京東這樣的互聯網電商巨頭,利用場景、供應鏈及海量用戶資源,規模化積累真人實操多模態數據。對內持續迭代自有具身大模型與服務機器人,補齊商用落地場景數據短板,對外將富餘標準化數據集對外開放銷售,打造新業務曲線。
熱錢能否催生數據新貴?
具身智能數據採集賽道具有兩個顯著的特點:
一個是熱,自2026年以來,多家機器人數據採集公司(包括純數據公司和重點打造數採業務的硬件、模型、本體公司)獲得孖展,孖展總金額超百億,企均10億的孖展額度,其中有它石智航、光輪智能、千尋智能、靈初智能4家企業完成10億元以上孖展,且同時有光輪智能、千尋智能、靈初智能、淵澈太初4家企業完成多輪孖展。
一個是新。數據採集賽道的新主要是體現在兩個方面,鑭瞳AI統計的10家企業中,有7家成立於2024年及以後,其中3家成立不足一年;二是,10家企業中,有7家是天使輪及更早的種子輪孖展,可以說是,資本啱啱開始聚集性關注。
對於一些成熟賽道,百億估值、10億孖展或許並不罕見,但對於一個尚在孕育期的賽道來說,卻實為罕見。
另一個有趣的現象是,在10家企業中,有3家企業背後站了多家機器人公司。例如,智元機器人投資了靈初智能的種子輪孖展;智域基石的天使輪孖展來自4家機器人公司,分別是靈初智能、穹徹智能、浙江人形、智平方;而覓蜂科技則是由智元機器人孵化而來。這或許就是機器人產業玩家用真金白銀表達的對數據的渴求。
不同公司做機器人數據採集,成本賬怎麼算?
然而,數據採集初創公司的孖展熱只是賽道火熱的一個縮影。在數據採集賽道中,還站着另外兩類強勢玩家:
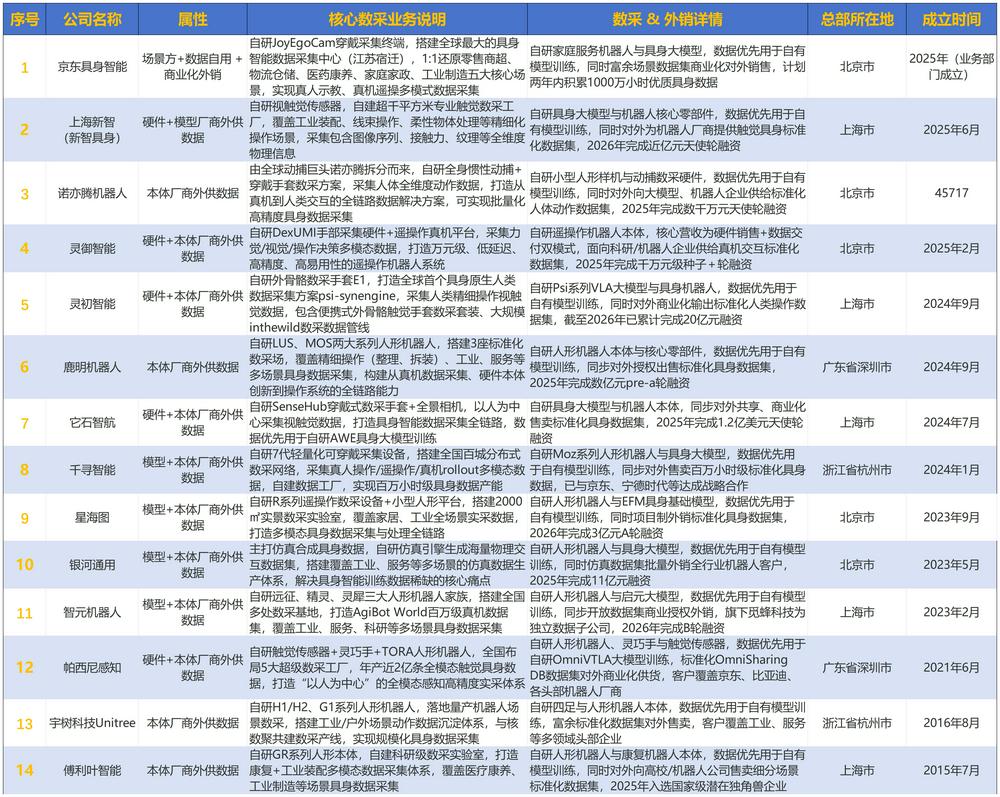
一類是硬件、模型、機器人本體公司;硬件公司主要來自靈巧手、觸覺傳感器等零部件賽道,它們的數據採集是充分發揮自身產品的能力,多是為硬件產品銷售服務。例如帕西尼感知科技新建4座超級數據採集工廠,鹿明機器人建成3個標準化數採場。模型及本體公司的數據採集業務多為服務自身數據需求,但是起步較早,現在已經形成了規模化覆蓋,例如,智元機器人已在上海、四川等地建立數據採集工廠,覆蓋家居、餐飲、工業、商超和辦公等多類真實場景。
另一類是還有一類是京東這樣的大廠,它創造性的將社會資源與數據採集相結合,建造了京東宿遷數採中心,發動群衆及各行各業工作人員在康養中心、居民社區、服裝工廠、獼猴桃果園等不同場景採集數據。
據水清木華研究中心發布的《2026年具身智能機器人數據產業佈局研究報告》,2025年具身智能數據全球市場總規模強勢突破達到2.42億美元,按年增長181.4%。2025-2030年全球市場複合年增長率(CAGR)將達85.0%,2030年總規模將攀升至52.5億美元。
2025年,中國具身智能數據總規模達到5.0億元人民幣,按年增速高達203%,這一增長率超出了全球同期平均水平接近20個百分點。
從商業化的角度,上海覓蜂具身智能科技有限公司董事長兼 CEO姚卯青在接受媒體採訪時表示,目前數據需求方大致集中在大模型團隊、海內外大廠以及初創機器人公司,且目前處於供不應求的狀態。
多家數據採集公司公開的訂單情況也印證了這一點。據公開信息,2026年第一季度,光輪智能新增訂單達5.5億元,靈御智能意向訂單約3億元,在手訂單約1億元,今年預計出貨約1000台。
然而,供不應求的背後,數億金額的訂單可以賺到錢嗎?
我們綜合幾個數據來算算賬,姚卯青曾透露,一個專業遙操員,8小時工作大概能平均產出2到3小時的有效數據。據行業數據,當前國內市場真機數據的價格在500元到1000元/小時,即每天可創造價值1000-3000元不等。
從成本端來看,根據BOSS直聘信息,機器人數據採集員的月薪在1-1.5萬元,按照每月21.75個工作日覈算,每人每天成本460-690元不等。機器人硬件成本是另外一個重要成本中心,以智元機器人數據採集工廠使用的遠征A2為例,其青春版售價20萬元左右,按照使用3年計算,每年折舊成本6.67萬元,約合每天255元。
再加上人員工資外的成本、採集配件成本及數採工廠運營成本、數據加工成本、存儲成本等等,綜合來看,數據採集產業並不賺錢,或者說毛利不高。
再看無本體採集,京東採用的是 EGO(第一人稱視角)數據採集,據披露,這種採集方式下,約 3%–20%含高價值、標註清晰、無冗餘的操作片段。按此計算,每天採集6小時,每月採集180小時,高價值數據僅為5.4小時-36小時,取價格中間值估算(約170–500元/小時,取中間值335元),每人每月創造商業價值1800-12000元不等,而每位採集員每月工資4000元。與上述智元的本體採集一致,若刨去其他運營及數據加工成本,賺錢也不容易。
純數據公司押注的是數據將從底層驅動具身智能產業奇點時刻的到來,而硬件本體公司不得不深入其中,更多是去尋找一個機器人本體、零部件等業務佔領先機的可能性;京東則是寄望於就地將供應鏈場景資源轉化為商業化數據增量。
細算成本賬,數據本身能否變現有極高門檻,考驗不同類型公司的綜合能力。畢竟,無論是企業還是資本都很難堅定的等待一個十年後的可能性。因此,當下能否賺錢,也是評判這是不是一門好生意的重要一點。