
作者|周一笑
郵箱|zhouyixiao@pingwest.com
北京時間3月20日,AI編程工具Cursor發布了自研模型Composer 2,宣稱是公司首次對基座模型進行「繼續預訓練結合強化學習」的成果。發布博客裏沒提基座模型的來源,措辭像是在說,這是Cursor自己從頭煉出來的。
不到兩小時,一個名叫Fynn的開發者在調試Cursor的API時,截獲了Composer 2的真實模型ID,kimi-k2p5-rl-0317-s515-fast。拆開來看,kimi-k2p5指向Kimi K2.5,rl是強化學習(Reinforcement Learning),後面是日期和版本號。
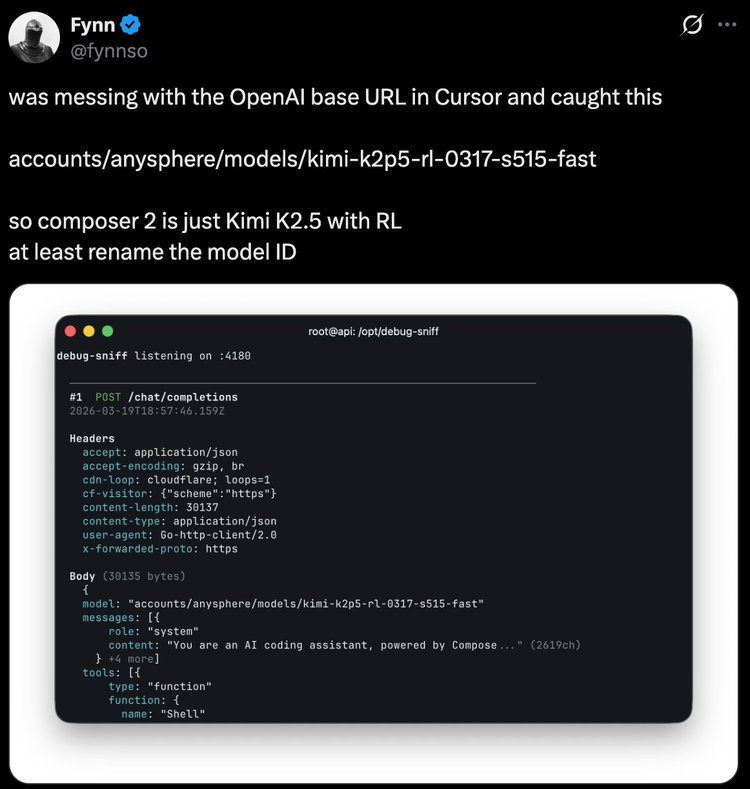
月之暗面預訓練負責人杜宇倫第一時間發推,稱團隊測試了Composer 2的tokenizer,發現與Kimi的tokenizer「完全一致」,幾乎可以確認「這是對我們模型的進一步微調」。他直接@了Cursor聯合創始人Michael Truell,質問為什麼不遵守許可證,也沒有支付任何費用。這條推文隨後被刪除。
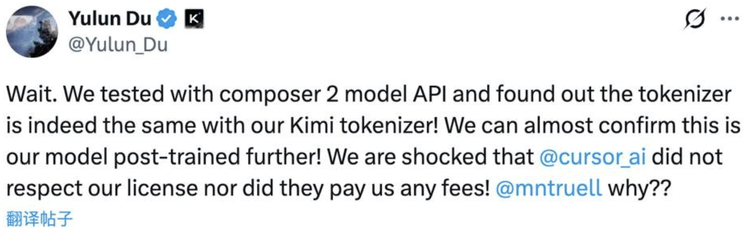
但火已經燒起來了。馬斯克在Fynn推文下面回覆了一句「Yeah, it's Kimi 2.5」,直接把事情拱上了熱搜。

從「套殼」到「合作」,反轉只用了幾個小時
Kimi K2.5採用修改版MIT許可證,明確要求月營收超過2000萬美元或月活超過1億的商業產品,必須在用戶界面上醒目標註「Kimi K2.5」。Cursor的年化收入約20億美元,超出這條門檻8倍有餘。
但就在輿論發酵的同一天,劇情反轉了。月之暗面官方賬號@Kimi_Moonshot發帖,口吻從質疑變成祝賀,稱「我們很自豪看到Kimi K2.5為Composer 2提供了基礎」,並澄清Cursor通過推理服務商Fireworks AI獲得了授權使用。

Cursor聯合創始人Aman Sanger隨後解釋說,團隊對多個基座模型做了評估,Kimi K2.5是「最強的」,之後在此基礎上做了額外預訓練和4倍規模的強化學習。他承認沒有在發布博客中提及Kimi K2.5是一個失誤。

從開源協議爭議到官宣合作,整個過程不到24小時。
Cursor為什麼「失誤」
這也不是Cursor第一次被發現「底座來自中國」。2025年11月Composer 1發布時,社區通過tokenizer分析推測它與DeepSeek高度一致,推理時偶爾還會輸出中文。當時Cursor同樣沒有回應。
從DeepSeek到Kimi,Cursor自研模型的底座換了一輪,都指向同一個事實,全球編程能力最強的底座模型,出自中國的開源社區。
Cursor不願公開底座來源,背後有一個更深層的結構性問題。Cursor一直以來依賴Anthropic和OpenAI的模型來驅動產品,但這兩家公司現在正親自下場做編程工具,Claude Code和Codex都在迅速鋪開,不少開發者已經開始遷移。Cursor面臨的悖論是,它必須依賴頂級模型來滿足用戶需求,但模型廠商同時也是它的直接競爭對手。如果沒有自己可控的模型底座,Cursor就永遠受制於人。
從這個角度看,選擇中國開源模型微調幾乎是一個必然的邏輯,既夠強,又不會變成自己的競爭對手。但這同時也是Cursor不願公開講的原因,2025年它是AI編程賽道最炙手可熱的明星,估值衝到293億美元,3月12日Bloomberg報道新一輪孖展目標估值約500億美元。在這個節骨眼上承認核心模型來自中國開源社區,對估值敘事並不友好。
Composer 2在Cursor自己設計的CursorBench上拿到了61.3分,超過了Claude Opus 4.6的58.2分,不過這畢竟是一份自家出題自家考的成績單。反過來看,如果一個基於開源模型微調的產品能在編程任務上和巨頭打得有來有回,這件事本身可能比Cursor的披露失誤更有意思。Hugging Face聯合創始人Clément Delangue就此評價說,「中國開源現在是塑造全球AI技術棧的最大力量」。
而對月之暗面來說,這場風波的結果幾乎是一次完美的品牌事件,從「被侵權方」到「合作方」,在全球開發者社區裏刷了一輪存在感,最後還讓Cursor親口確認「選了Kimi K2.5因為它最強」。
Kimi的「黃金一周」
往前倒推幾天,Kimi剛經歷了一個密度極高的曝光周期。
3月16日,月之暗面發布了一篇純架構層面的技術論文「Attention Residuals」(注意力殘差),試圖替換掉Transformer架構中一個自2015年ResNet以來就幾乎沒人動過的基礎組件,殘差連接。過去每一層的輸出和輸入直接相加、無差別傳遞,Kimi團隊讓每一層可以「回頭看」,動態選擇從前面哪些層提取信息。實驗顯示訓練效率提升約25%,推理延遲增加不到2%。論文的共同一作之一是一位17歲的深圳高中生,和Kimi的關鍵研究者蘇劍林、張宇並列。
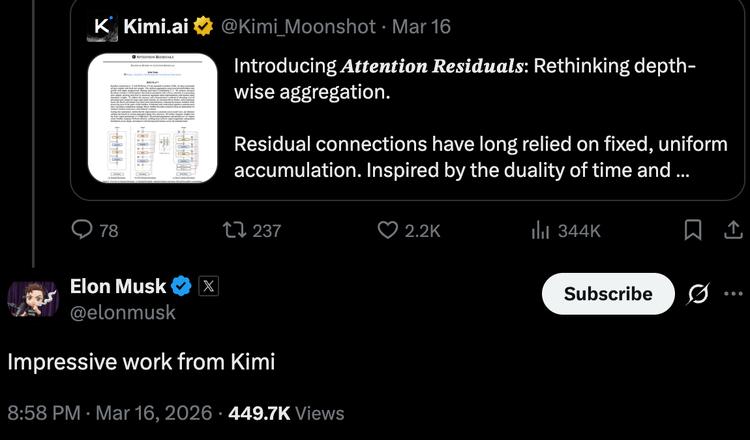
論文發出當晚,馬斯克在X上評價「Impressive work from Kimi」,Kimi官方回了一句「你的火箭造得也不錯」。Andrej Karpathy說,「看來我們還沒把'Attention is All You Need'這句話按字面意思理解透」。前OpenAI強化學習VP Jerry Tworek稱之為「深度學習2.0」的開端。
第二天,3月17日,黃仁勳在GTC 2026的Keynote中多次提及中國開源模型。Kimi K2.5代替了去年的DeepSeek ,成為黃仁勳用來對全世界展示推理重要性的時候,那個作為標杆的模型。
3月18日,楊植麟更是直接登上GTC的分論壇演講。他是嘉賓名單中唯一來自獨立大模型創業公司的代表,與特斯拉AI總監、DeepMind核心架構師同列。演講現場也座無虛席,他系統披露了Kimi K2.5背後的技術路線,將模型進化歸納為Token效率、長上下文和智能體集群三個維度。
而在DeepSeek徹底走紅之前,在GTC上做分享最多的中國開源模型團隊,曾經是DeepSeek。
論文、GTC、Cursor,三件事在一周內接連落地,且這些亮眼的高光裏都有與DeepSeek「時代更替」的意味:曾經是DeepSeek 每篇論文都被全球技術社區和KOL大佬追捧轉發,曾經GTC幾乎是DeepSeek的「非官方」發布會,甚至Cursor以前「悄悄套殼」的也是DeepSeek ,而一瞬間,全部變成了月之暗面Kimi。
站在DeepSeek的位置上
這讓很多人開始意識到,Kimi正在佔據DeepSeek在全球AI社區中的位置。
DeepSeek R1在2025年初的爆發重塑了整個行業的認知,讓「中國AI」從一個模糊的概念變成了具體的、可以運行的模型權重。但自那之後,DeepSeek相對沉寂了。社區期待已久的V4/R2一直沒有發布,V3.1、V3.2等版本持續在更新,但那種「一出手就改寫規則」的衝擊感暫時沒有重現。
Kimi恰好踩進了這個窗口期。
2025年春節後,Kimi日活一度承壓,月之暗面砍掉了大筆營銷預算,閉門做模型。7月,Kimi K2發布,萬億參數MoE架構。K2發布後在Hugging Face上線首日下載量超過平台上所有其他模型,Anthropic聯合創始人Jack Clark評價其為「全球最好的開源權重模型」。
2026年1月底,K2.5發布,原生多模態加Agent集群架構,在多項Agent評測中拿下全球開源最佳。OpenClaw熱潮到來後,Kimi Claw迅速上線。據報道,K2.5發布不到一個月,Kimi近20天累計收入就超過了2025年全年。Stripe數據顯示,Kimi個人訂閱用戶1月支付訂單按月增長8280%。
資本層面的節奏也在加快。2025年底5億美元C輪,投後估值43億美元;2026年2月超7億美元,估值升至100億美元;3月中旬新一輪10億美元正在推進,估值已到180億美元。同期港股上市的智譜和MiniMax,市值在3月中旬分別站上了3300億和3800億港元的量級,月之暗面還沒進二級市場,以當前AI板塊的溢價看,上市後的想象空間不小。

Kimi就這樣用DeepSeek的方式奪走了DeepSeek的光環。
Kimi K2的架構直接脫胎於DeepSeek V3,MLA注意力機制、MoE專家混合框架都是DeepSeek首創或率先大規模驗證的。Kimi的崛起本身就是DeepSeek技術影響力的一種繼續。DeepSeek的開源策略也更為徹底,採用純MIT許可證,沒有任何營收門檻限制,這讓它在全球開發者生態中積累了極高的滲透率。Kimi的修改版MIT許可證在商業使用上多了一層約束,這次Cursor事件就是一個例子。
在DeepSeek相對安靜的這段時間裏,Kimi接過了「中國AI開源代表」的話筒。無論是黃仁勳的演講台、Cursor的模型底座,還是學術論文和開發者社區,Kimi正在填補一個需要持續有新鮮內容的敘事空間。
而且Kimi做的也不只是出模型,Attention Residuals論文觸碰的是深度學習十年沒有實質性變化的底層結構,這和DeepSeek當年做MLA是一個路數,都是在嘗試重新定義行業的基礎設施。
中國AI開源的故事,正在從「一個DeepSeek」變成一個不停有新的奪走光環的玩家出現的故事,這和硅谷的節奏越來越像,OpenAI之後是Google,Google之後Anthropic,然後循環。
由中國的開源模型們交替接管全球開發者們的時間線,模型能力螺旋式上升的同時,話語權不旁落:等到DeepSeek 新模型出現時,Kimi的注意力會不會被奪走;MiniMax、Qwen、智譜、階躍以及同樣來勢洶洶新入局的小米們的新工作,會不會再突然奪走它們倆的主角位置,這些都在讓這種螺旋交替繼續下去,而這對每個中國AI參與者都是好事。