「養龍蝦」這一波再次大大推動了AI尤其是端側AI的普及浪潮,也暴露了AI普及過程中亟待解決的諸多問題,對於整個行業的發展都有極大的促進意義。
比如部署和執行的難題,說明當下AI應用的門檻還是太高,不能只面向專業人士,於是各種一鍵安裝和集成的方案紛紛出爐,普通用戶也能玩轉了。
比如安全和隱私的難題,尤其是個人和機構、企業的敏感數據,不能輕易上傳到雲端,只能在本地處理,於是端側AI PC的能力有了更大的用武之地。
比如Token成本的難題,畢竟龍蝦這種智能體背後都需要調用大模型,而且是完全不顧及成本、近乎無法控制的調用,所以只有本地部署纔是最終的解決方案。

在這波浪潮中,擁有CPU+GPU+NPU三大引擎組成的完整端側AI硬件與算力的AMD自然不會錯過,第一時間發布了相關教程,推薦在銳龍AI Max+平台上部署OpenClaw,畢竟其最大128GB統一內存和96GB共享顯存的配置是非常適合的。
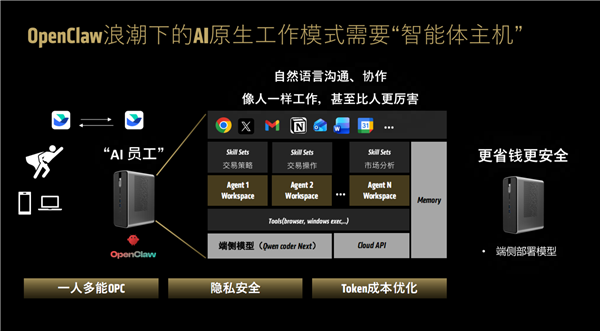
有趣的是,為了更好地滿足算力、安全、成本方面的需求,AMD還提出了一個新的概念——「智能體主機」(Agent Computer)。
簡單地說,AMD推薦大家在AI時代配備兩台電腦主機,其中一台滿足傳統的工作、生活需求,另一台專門用來跑AI,無論是開發還是應用,無論是端側還是雲側,尤其是跑各種智能體,實現專機專用。
AMD認為,智能體主機,將是計算發展史上的又一個里程碑,可能會和一路走來的電子管計算機、大型機/小型機、PC個人電腦、互聯網、移動互聯網、雲計算一樣,意義重大。

AMD認為,無論是交互方式還是應用方式,智能體主機和傳統PC都截然不同,因為後者是用戶操作驅動的,而智能體主機是以AI智能體持續運行而驅動的。
具體來說,智能體主機不再需要傳統的鍵鼠顯示器等人機交互渠道,也不需要人坐在電腦前,手動打開應用,再一步步執行,而且每一步都等待人的精確指令、任務安排。
它的一切都由AI智能體自主驅動,可以永遠在線、連續工作,運行各種其他智能體,而且可以通過各種即時通信軟件,隨時隨地交互,獲得想要的結果。
你不需要像對待PC那樣親自操控它,只需將任務委託給它即可。
你在微信上發送一條消息,AI智能體就會開始行動。
你在Slack中提交一個任務,AI智能體就會接手處理。
你在Messages裏詢問進度,AI智能體就會向你反饋結果。
這就是完美的賽博牛馬啊!一人公司(OPC)真的可以實現了!

當然,要成為合格的智能體主機,尤其是既要高性能還要低成本,的確是有一定門檻的,除了基本的算力之外,最關鍵的就是顯存容量要足夠大。
作為最基本的要求,為了滿足全面的SOP標準程序要求,處理好記憶文件、技能規範、自學習上下文等,也就是養好一隻基本素質齊全的「龍蝦」,顯存不能小於10GB。
如果是一人帶N個AI員工,分管不同業務方向,就得考慮技能、上下文的膨脹和併發,顯存就得是N個10GB。
為了提升AI員工的「工作經驗」,私有知識庫是不能少的,這就得考慮不少於20GB顯存空間。
為了保證AI員工的基本素質隨時可用,而不是每次都調用雲端大模型(token費用就花不起啊),就得在本地有一個至少35B參數的大模型,這就得喫掉25GB以上的顯存。
綜上,要想打造一台能帶動多個智能體或者說多個AI員工的智能體主機,得保證可用顯存至少有64GB。
如果用獨立顯卡,那怎麼也得三四塊高端卡,成本相當嚇人,而換成AMD銳龍AI Max平台的話,甚至不需要獨立顯卡!

銳龍AI Max平台的優勢大家應該不陌生了:
CPU方面是Zen 5高性能架構,最多16個純大核,最多80MB緩存。
GPU方面是RDNA 3.5架構的最多40個CU單元、32MB無限緩存,顯存位寬256-bit。
NPU方面是XDNA 2架構,峯值算力60 TOPS,原生支持Windows 11 AI+ PC特性。
內存更是支持UMA同一架構,四通道256-bit位寬、8000MT/s高頻率完美匹配GPU,最大容量128GB,可劃分最多96GB作為專用顯存,構建智能體主機堪稱完美。

根據測試,銳龍AI Max+ 395的端側AI推理性能着實亮眼。
基於Qwen 3.5 35B A3B大模型跑單個OpenClaw框架的智能體,輸出速度可高達45 tokens/s,,處理10000個輸入token只需要大約19.5秒,並支持最大26萬上下文長度,而且可以同時跑最多6個智能體,每一個的上下文長度都能達到9.5萬。
換成更大規模的Qwen 3.5 122B A10B模型跑,單個智能體的輸出速度仍然可以接近20 tokens/s,還能同時跑兩個9.5萬上下文長度的智能體。
另外,Qwen3-coder -next代碼優化模型的推理速度超過40 tokens/s,完美滿足代碼開發、調試等場景。
GPT-OSS-120B開源模型的推理速度更是能夠超過50 tokens/s,是所有測試中單智能體速度最快的。


經過長時間的培育,銳龍AI Max平台的產品已經十分豐富,衆多品牌推出了全形態產品,覆蓋Mini工作站、水冷工作站、移動工作站、筆記本、一體機甚至是掌機等,可實現全場景覆蓋。
它們都基於Windows 11操作系統,符合更多人的使用習慣,無論開發還是應用都有着廣闊的生態支撐。
即便內存價格瘋漲,銳龍AI Max產品的價格也可以控制在2萬元出頭,相比之下無疑是最實惠的AI主機方案。


基於銳龍AI Max+ 395的迷你AI工作站具備諸多不可替代的優勢,包括但不限於體積小巧便於本地部署和攜帶、數據隱私安全有保障、TCO成本優化、x86 Windows成熟生態、工作環境友好等等。
對比以往需要部署在機房的大型塔式工作站方案,基於銳龍AI Max+ 395的迷你AI工作站可以將體積縮小至僅僅十分之一,功耗降至十分之一乃至更低,模型參數量則能擴大兩三倍。
通過AMD與產業夥伴的通力合作,目前採用銳龍AI Max+ 395平台的AI和智能體解決方案已經非常豐富,行業白皮書就發布了多達11部,覆蓋衆多行業領域:財稅、教學、醫療、法務、數字人、招投標、數據分析、辦公助手、會議系統、保險理財、供應鏈管理,等等。

比如針對醫療資源不均衡、人人都想看專家的看病難問題,晶耀智遠打造了AI多智能體醫療科研解決方案。
它以銳龍AI Max+ 395為核心算力底座,形成了適配醫院科室的本地化、輕量化、高算力的智慧醫療服務體系,集成醫療專用算法和專家知識庫,融入專科醫生的思維鏈,6大功能智能體可全面覆蓋診療、建檔、預警、應急等場景,有效解決了對醫療專業模型幻覺、數據管理難等痛點。

在教育行業更是實現了全場景覆蓋的解決方案矩陣,覆蓋教學、科研、教務、管理等四大教育核心環節,遍佈同濟大學、北京大學、南京醫科大學、復旦大學等等,都運行在不同品牌的銳龍AI Max+ 395迷你工作站上。
比如為了解決高校科研人員研讀海量專業論文費時費力的問題,Ryypol創新性地將靜態論文轉化為「可交互對話」的智能體,不僅能隨時解答文獻疑問,更能深度解析晦澀原理,利用「文生圖」技術將抽象概念直觀可視化。
比如行者AI的校園智算終端解決方案,以自研多模態大模型為核心,融合AI+美術、AI+音樂技術,提供AI繪畫、智能評測、互動創作、詞曲生成等一體化能力,目前已覆蓋30餘個省市、300多所院校。
2025年普遍被視為「智能體元年」,OpenAI創始人之一Andrej Karpathy則認為,2025年是我們進入「智能體元十年」的開端。
很顯然,智能體將在很長一段時間內處於起步階段,衆多技術和非技術原因都註定了它不可能快速成熟、普及,需要通過硬件、軟件、生態等各方面的持續大力培育。
「養龍蝦」的火爆很好地印證了這一點。它一方面吸引了更多人嘗試智能體,另一方面也暴露了諸多亟待改進的問題,包括如何降低使用門檻、如何保證安全、如何節省成本等等。
在這方面,AMD憑藉全方位領先的AI技術和產品,做了很好的努力和嘗試,提供了一個非常好的思路。

可以說,AMD銳龍AI Max系列平台堪稱當今Windows端側AI算力的天花板,也是養龍蝦這種本地智能體運行的理想底座。
憑藉Zen 5 CPU、RDNA 3.5 GPU、XDNA 2 NPU三大先進架構算力引擎,獨特的128GB超大統一內存、96GB超大動態顯存能力,再加上豐富的產品形態、成熟的Windows 11生態系統,銳龍AI Max系列絕對是智能體主機的首選平台,全面實現跑得多、跑得快,還省錢,又安全。
也許,你真的需要考慮來一台「龍蝦專用機」了!
