过去几个月,AI 圈一桩桩版权案接连爆出。
迪士尼拉着环球影业,把 Midjourney 告上法庭,指控它在没打一声招呼的情况下,就学会了画《星球大战》和《小黄人》。

图片巨头 Getty Images 则抓住了 Stability AI 的现行—— AI 不仅“吃”了它数百万张带版权的图片,甚至在生成的新图里,还心虚地“吐”出了那个标志性的水印,像个作案后忘了擦掉指纹的笨贼。

这些案子的起因都源于那个让所有 AI 公司夜不能寐的问题:用来训练模型的海量数据,究竟算不算“赃物”?
最近,两场判决落槌,似乎给出了一个答案。Anthropic 和 Meta 在版权官司中都获胜让许多人以为警报已经解除。但细看之下,这场胜利并非这么简单——法官在判决书里悄悄留下了一串解开谜题的钥匙。
从表面上看,案情并不复杂。一群作家指控这两家公司用他们写的书来训练大模型,这是偷窃。AI 公司则辩称,这叫“变革性使用”,是学习,不是抄袭,属于法律允许的“合理使用”。
出人意料的是,法官采纳了 AI 公司的说法。他们认为,用书籍训练 AI,和直接复制书籍来卖是两码事,确实有“变革性”,而且原告作家们也没能拿出有力证据,证明自己的书因此就卖不出去了。
于是,判决落下,AI 公司赢了。至少,新闻标题是这么写的。
但就像所有精彩的故事一样,真正的玄机藏在细节里。法官的判词,就像那个无意中为破案留下伏笔的警官,充满了暗示。
在 Meta 的案子里,Chhabria 法官几乎是手把手地给原告“复盘”。他毫不留情地指出,原告的诉讼策略简直一团糟。“判决并不意味着Meta的行为就合法了,”他写道,“只是因为这批原告没能说服我。他们问错了问题,也拿错了证据。”
这番话,无异于在法庭上公开递出了一份“诉讼指南”:这次算你们侥幸过关,下次来个更懂行的,结局就难说了。
另一边,审理 Anthropic 案的 Alsup 法官,则对另一件事耿耿于怀:这些 AI 公司用来训练的数据,很多是从盗版网站上扒下来的。“原罪”问题,让他十分恼火。
“你们明明有合法渠道,却偏要走捷径,”他警告道,“用非法手段获取的东西,别指望能用‘合理使用’这块挡箭牌来洗白。”他甚至补充说,后来再去合法扫描,也抹不掉最初的“偷窃”行为。
这番话,等于在 AI 公司看似坚固的胜利堡垒上,预埋了一颗定时炸弹。今天的问题解决了,但历史旧账随时可能被翻出来。

而真正致命的威胁,是那个被这两场官司巧妙绕开的问题:AI“说”出来的话,算不算侵权?
训练过程可以被解释为“学习”,但如果 AI 能一字不差地“背诵”出《哈利·波特》呢?最近的一项研究就揭示了这个令人不安的事实:Meta 的模型记住了《哈利·波特与魔法石》超过 40% 的原文。AI 不再只是个学生,它成了一个藏着海量盗版书的移动硬盘。
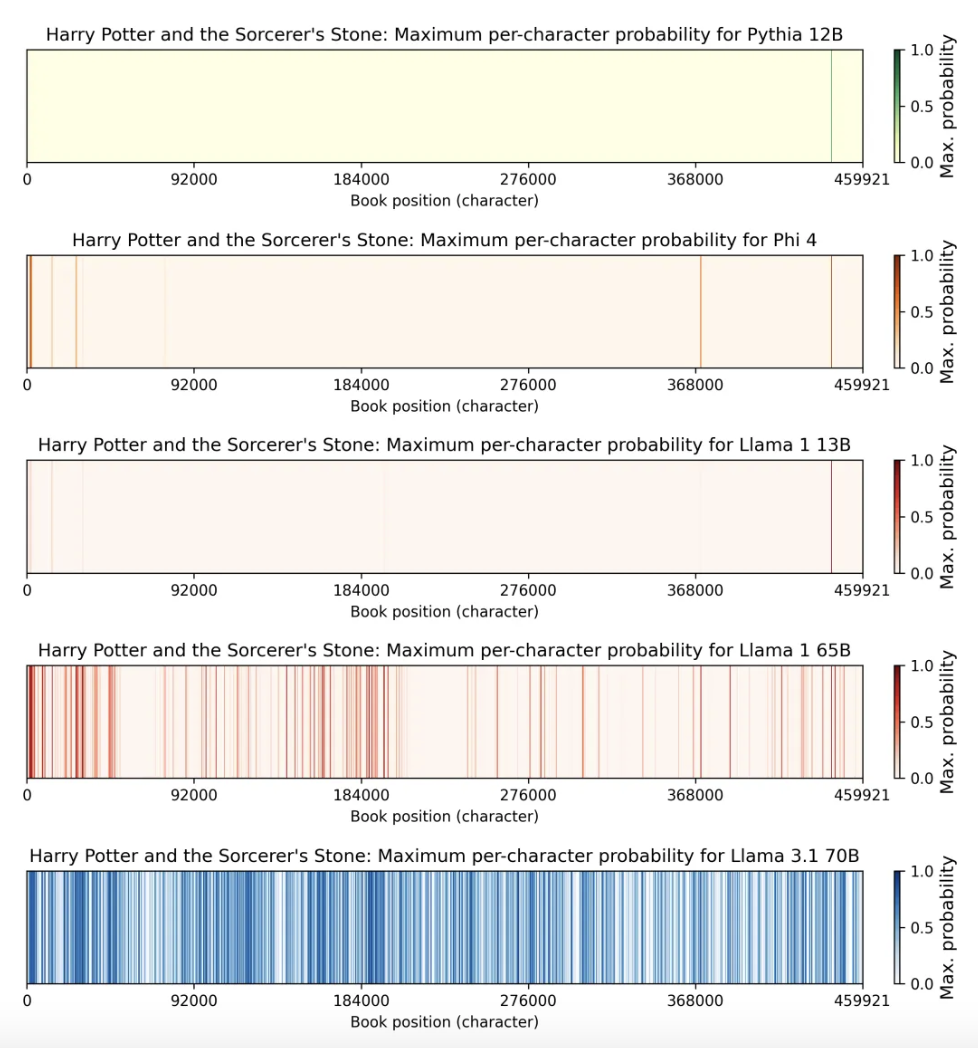
该图表显示了让模型从《哈利·波特与魔法石》各部分生成 50 个 token 的摘录的难易程度,线越深,重现该部分内容就越容易
对此,Alsup 法官也早已划下红线:“如果 AI 的输出内容直接抄袭了原作,那就是另一回事了。版权方完全可以拿着这些证据,再告一次,而且胜算会大得多。”
所以,这场胜利到底意味着什么?
对于 Meta、OpenAI 这样的巨头来说,这或许只是争取了更多的时间。他们财力雄厚,背后是顶尖的律师团队,已经开始花钱与各大媒体和出版商签署授权协议。对他们而言,版权问题正在从一个法律风险,转变为一项可以计算的商业成本。
但对于那些规模较小、依赖开源数据的 AI 公司来说,警报远未解除。他们没有雄厚的资本去支付天价的授权费,也经不起漫长的官司消耗。一旦版权的“清算”全面开始,他们很可能就是第一批倒下的。
而对于创作者来说,局面则更加复杂。他们或许有机会通过授权获得一些收入,但这笔钱,能否弥补一个被 AI 内容冲击得七零八落的市场?
说到底,这两场官司并没有给出一个最终答案,反而让问题变得更具体、更棘手了。这场围绕版权的博弈,没有因为几次判决而结束,它只是从法庭上的唇枪舌剑,延伸到了谈判桌前的真金白银。
这场关于数据、创意与 AI 的博弈,或许才刚刚开始。