炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!

强化学习(RL)到底是语言模型能力进化的“发动机”,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?
过去的研究多数持悲观态度:认为 RL 带来的收益非常有限,有时甚至会让模型“同质化”加重,失去多样性。然而,来自英伟达的这项研究指出,造成这一现象的根本原因在于:数学、编程等任务在 base model 的训练数据中被过度呈现,以及 RL 训练步数不足。

ProRL 来了!长期训练 = 推理能力质变!
由 NVIDIA 团队提出的 ProRL(Prolonged Reinforcement Learning)框架,将 RL 训练步数从传统的几百步大幅提升至 2000 步以上,释放了小模型潜藏的巨大潜力。结果令人震惊:
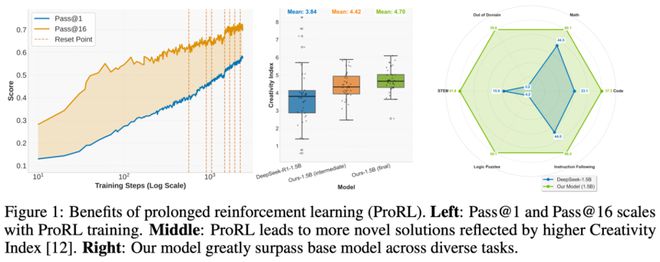
这一突破主要来自于稳定长期的强化学习,然而,长期 RL 训练并不容易,容易出现熵崩塌、性能震荡、甚至“摆烂”。为此,团队构建了完整的技术组合拳:
引入了数学、编程、科学问答(STEM)、逻辑谜题、指令遵循等多领域数据,这些任务具有程序化可验证的正确答案,为 RL 训练提供了可靠、客观的监督信号,不再依赖“易被骗”的奖励模型。
在 GRPO(Group Relative Policy Optimization)框架基础上,融合 DAPO(Decoupled Clip and Dynamic Sampling)关键的解耦裁剪(Decoupled Clipping)来避免策略更新失衡,以及动态采样(Dynamic Sampling)来过滤掉“太容易”或“完全不会”的无效样本,提升训练效率。
与一些去 KL 正则的做法相反,本论文发现适度 KL 惩罚是稳定训练的关键。同时引入参考策略重置机制:当 KL 骤增或性能下滑时,重置参考策略为当前模型副本,并重置优化器,让训练“重启”。这个简单机制有效打破训练停滞,使模型持续进化。
基于 ProRL 技术,团队训练出 Nemotron-Research-Reasoning-Qwen-1.5B,展现出惊人的性能优势:
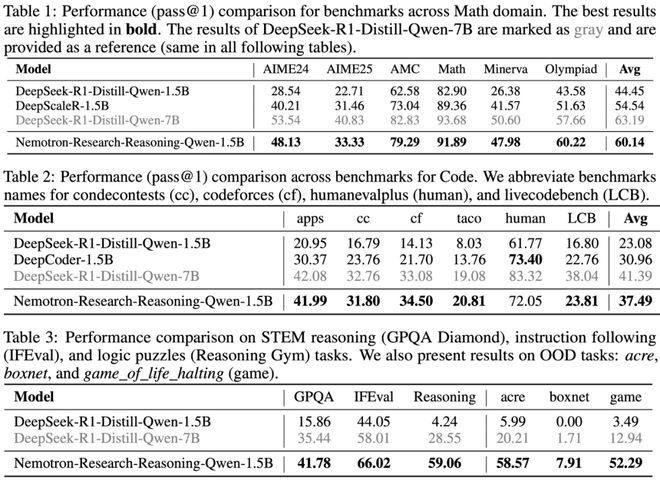
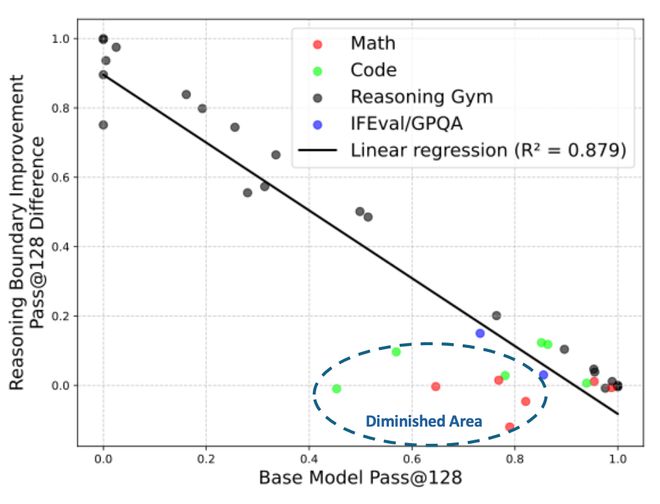
ProRL 真的能够拓宽模型能力边界
近来,对于 RL 是否能够拓宽模型的能力边界一直有争议。作者在文章中着重分析了 RL 是否能够拓宽能力边界的问题,并且发现,长期稳定的 RL 能够带来模型能力的真正提升。围绕着这个主题,文章主要揭示了三个方面的发现:
总结
这项来自 NVIDIA 的研究,让我们重新认识了 RL 的真正潜力——不仅能优化策略,还能扩展模型的能力边界。
通过 ProRL,我们第一次看到“小模型”也可以在复杂推理任务中“迎难而上”,甚至跑赢大模型。而这种进步,不靠更多数据、不靠更大模型,只靠更长、更稳、更聪明的训练流程。
未来,如果你想做出推理能力强、部署成本低、泛化能力强的小语言模型,ProRL 可能正是那把钥匙。